
Chaque jour, il y a 4 millions d’articles de blog, 100,000 articles de news et 500,000 heures de vidéos publiées sur Internet. Une richesse d’informations et de connaissances. Une richesse d’informations et de connaissances qui est perdue pour beaucoup d’entreprises, du moins pour la plupart.
Perdue ?
Première étape : la curation de contenu
Pas totalement. Grâce à la technologie de la curation de contenu, nous pouvons maintenant filtrer le web. Avec des outils de curation de contenu, et des platefomes comme Scoop.it (parmi tant d’autres bien sûr), nous avons plusieurs possibilités, plus ou moins sophistiquées, pour filtrer cette énorme quantité de contenu qui est publiée tous les jours, en se focalisant sur ce qui importe le plus. Une bonne curation de contenu est essentielle. Cela fait gagner beaucoup de temps sur la découverte de contenu à partager dans une logique marketing ou pour aider les organisations à prendre de meilleurs décisions.
Et peut être, plus important encore, sans ces filtres, nous serions uniquement capables de chercher, pas de découvrir.
Mais jusqu’à récemment, toutes les solutions que nous avons proposées pour faire face à la surcharge d’informations – la nôtre incluse – tournaient autour de la même idée de base : des filtres plus – ou plus sophistiqués -.

Cela signifie que jusqu’à présent, l’analyse et la compréhension du contenu filtré par un outil de curation de contenu restaient à faire entièrement par son utilisateur.
Et cette partie – analyser et comprendre le contenu – est également critique.
Quand nous regardons ce que nos utilisateurs qui réussissent le mieux font – qu’ils soient des content marketeurs, des analystes de market intelligence, des professionnels indépendants ou des éducateurs – ils partagent tous quelque chose. Ils ne filtrent pas seulement les informations, ils passent du temps à les analyser et à comprendre ce que cela signifie. La pratique de la curation de contenu les a aidés à développer une compréhension profonde de leurs sujets. Ils disent que les meilleurs écrivains sont des lecteurs. Nous voyons également cela se produire sur la plateforme Scoop.it.
Six ans après le début de l’aventure Scoop.it, je continue à parler aux utilisateurs et aux clients chaque jour. Cela me permet de rester ancré dans la réalité du terrain et cela m’aide à mieux comprendre leurs attentes. Et ce qui ressort des centaines de conversations que nous avons eues, c’est qu’il y a un énorme besoin d’un outil qui permette une meilleure compréhension de ce qu’est le contenu et de ce que cela signifie :
- Les spécialistes du marketing de contenu veulent comprendre les sujets sur lesquels ils doivent créer du contenu et comment créer le meilleur contenu possible sur ces sujets,
- Ils veulent comprendre qui a du succès sur ces sujets – qui est influent – afin qu’ils puissent trouver de l’inspiration ou des partenaires potentiels de co-marketing,
- Les marketeurs en général veulent savoir si leurs actions marketing ont un impact – en général mais aussi par rapport à leurs concurrents,
- Les market analysts veulent comprendre les sujets d’actualité et l’évolution des conversations sur ces sujets afin qu’ils puissent comprendre plus facilement ce que cela signifie pour leur stratégie.
En résumé, nous avons appris qu’au-delà de la curation de contenu, ils avaient besoin de connaissances et de données exploitables pour donner du sens au contenu Web.
Ce dont ils avaient besoin, c’était de la content intelligence.
Étape 2 : la collecte des données
Donc, en 2016, nous avons décidé de concentrer nos efforts de R&D pour apporter une solution à ce problème. Nous avons estimé que nous avions un atout unique pour cela : les données.

Au fil du temps et au fur et à mesure que la plateforme a été adoptée par plus de 4 millions d’utilisateurs, nous avons collecté beaucoup de données. En particulier, nous avons un moyen de savoir quand une nouvelle source produit un contenu intéressant. Chaque fois qu’un utilisateur Scoop.it scoop un article en utilisant notre extension de navigateur sur un nouveau site Web, nous avons une chance de qualifier ce site Web et de l’inclure dans la liste des sources de contenu que nous pouvons surveiller au fil du temps.
Avoir un tel volume de données est l’un des principaux facilitateurs ou algorithmes d’intelligence artificielle. Une grande partie de ce que l’IA fait aujourd’hui est de reconnaître les modèles. Mais pour ce faire, il faut apprendre de nombreux exemples. Très souvent, les entreprises qui ont développé des systèmes d’IA réussis l’ont fait parce qu’elles ont accès à beaucoup de données.
En surveillant des millions de sources Web pour les filtrer pour la curation de contenu, nous avons eu une mine d’or pour une plateforme d’IA.
Nous avons donc commencé à examiner plusieurs façons de tirer des enseignements intéressants des données que nous avions. Certaines ont échoué, d’autres n’ont pas été concluantes et, finalement, nous avons trouvé un moyen de produire des résultats pertinents et cohérents autour de l’identification des sujets à grande échelle.
Notre plateforme a appris comment déterminer le sujet d’un contenu et à quel point il était similaire à un autre.
Etape 3 : la content intelligence

Regrouper un grand volume de contenus en thèmes cohérents a été une avancée majeure. Cela nous permet de faire des choses telles que :
- Trouver ce qu’est un site Web. Par exemple, votre site Web ou le site Web de vos concurrents.
- Découvrir des sujets liés à un mot-clé donné. Par exemple, nous pouvons savoir quels sujets sont couverts par les 2 500 articles publiés le mois dernier avec un titre qui contient «content marketing».
Mais nous ne nous sommes pas arrêtés là.

Nous avons également enrichi nos données sur le contenu et ses attributs avec d’autres métriques : les métriques de performance (telles que les partages sur les réseaux sociaux) ou les métriques de qualité (telles que le nombre de mots ou la lisibilité). Et en ajoutant ces métriques dans le moteur, nous pouvons obtenir des informations encore plus intéressantes :
- Volume de contenu et popularité sur divers sujets.
- Benchmarks entre différents sites Web sur plusieurs sujets.
- Evolution de ces métriques au fil du temps.
- etc…
Du filtrage du Web à l’analyse et à la compréhension du contenu Web
Voilà où nous en sommes : l’été dernier, nous avons commencé à tester en interne un premier prototype de la nouvelle technologie que nous avions développée. Nous avons montré des résultats au cours de l’automne à certains de nos clients et nous menons maintenant des projets pilotes pour valider la valeur de nos idées.
Nous avons décidé d’en faire un nouveau produit autonome pour l’instant afin que nous puissions rapidement itérer et valider la proposition de valeur indépendamment des autres avantages de la plateforme Scoop.it, en particulier de ses capacités de curation et de publication de contenu.
Et nous l’avons appelé Hawkeye par Scoop.it.

Notre objectif avec Hawkeye est de fournir des données et des informations exploitables qui rendent le marketing de contenu plus prévisible. Personne ne crée de contenu dans le vide : notre contenu aura toujours du mal à attirer l’attention avec un volume d’informations de plus en plus conséquent. Le problème est qu’il est vraiment difficile de voir ce que chaque site ou influenceur concurrent fait sur un certain nombre de sujets – et encore moins de le mesurer. C’est beaucoup trop de travail. En tirant parti de l’intelligence artificielle, Hawkeye surveille, analyse et comprend le contenu de tout le Web pour aider les marketeurs à créer un contenu de meilleure qualité et à mesurer son impact.
Voici quelques-uns des rapports que Hawkeye peut déjà donner :
Analyser un sujet :
Une liste de topics liés à un certain filtre (par exemple : un mot-clé) avec le nombre de volumes (combien de contenu a été publié sur ce sujet) et la popularité (combien de fois ils ont été partagés). Voici par exemple une liste de sujets, Hawkeye a découvert que tous les articles mentionnant « content marketing » dans leurs titres, écrits en anglais et publiés au cours des 30 derniers jours étaient sur :
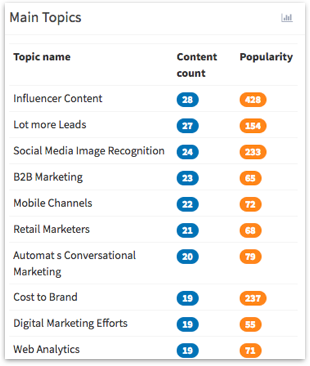
Cela peut aider à identifier les sujets les plus susceptibles d’être intéressants pour moi en tant que spécialiste du marketing de contenu (le volume faible, la popularité élevée car cela signifie que les gens s’intéressent à eux mais n’ont pas encore été couverts). Ou en tant que market analyst, je pourrais l’utiliser pour comprendre les nouvelles tendances sur lesquelles je pourrais me concentrer.
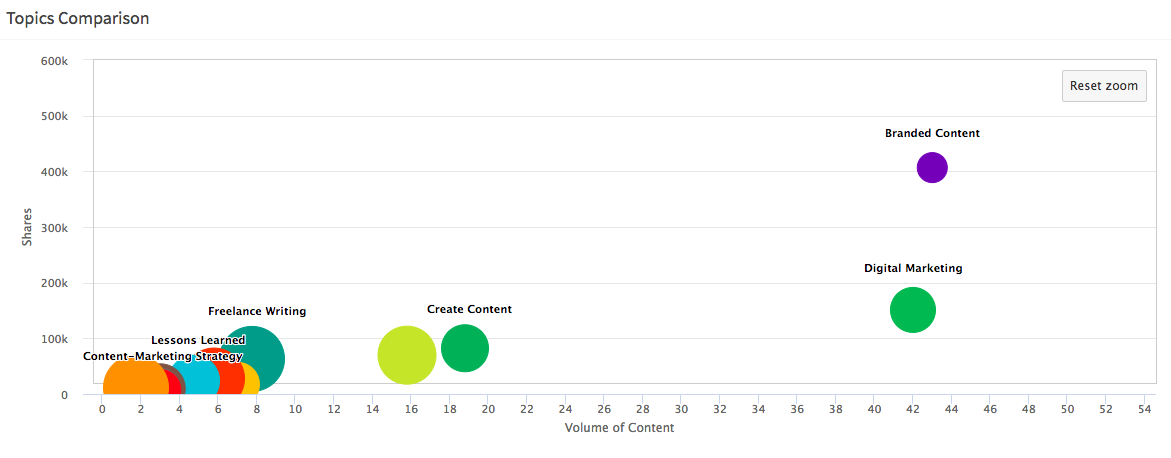
Hawkeye apporte la visualisation de données afin que vous puissiez avoir une idée des données ci-dessus d’une manière plus visuelle comme ce graphique :
Analyser le contenu des concurrents sur plusieurs topic
Au lieu de chercher tout le contenu lié à «content marketing», l’un des filtres que vous pouvez alimenter avec Hawkeye est simplement une liste de sites Web. En particulier une liste de concurrents ou de références de l’industrie. Hawkeye peut revenir avec des KPI de haut niveau tels que le volume de contenu vs partages :
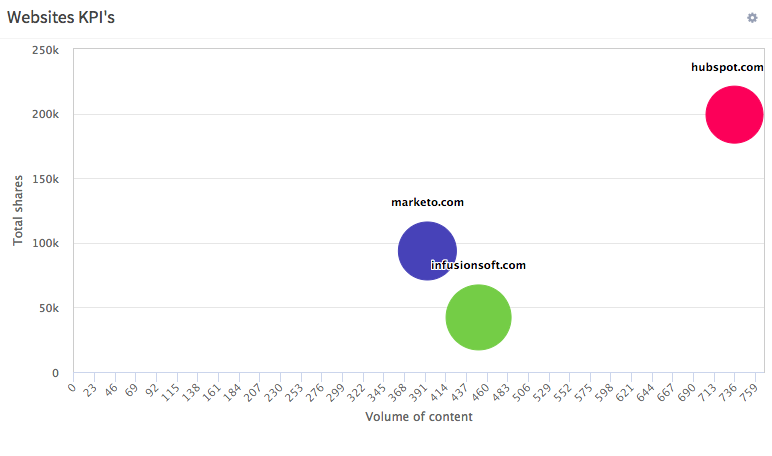
Cela peut vous indiquer si vous devez produire plus de contenu ou un meilleur contenu (ou les deux) pour rattraper vos concurrents.
Mais Hawkeye peut utiliser l’analyse de topics pour approfondir et analyser votre écart de contenu, c’est-à-dire les sujets sur lesquels vos concurrents se concentrent VS les sujets sur lesquels vous vous concentrez :
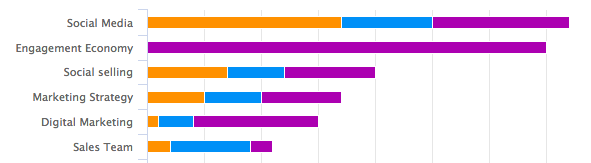
Cela vous aidera à comprendre où concentrer vos efforts, en particulier sur les topics sur lesquels vous devez créer du contenu.
Vous pouvez également analyser les parties spécifiques du contenu sur chacun de ces topics et par exemple obtenir le contenu le plus partagé sur ce sujet ainsi que le niveau de qualité de chacun de ces éléments de contenu :
Mesurer la part de voix et l’impact des earned médias sur tous les topics
Un contenu qui aide votre marque n’est pas seulement celui que vous produisez : c’est aussi ce que les gens disent de votre marque. Hawkeye peut non seulement surveiller les mentions de votre marque dans le contenu Web, mais aussi faire cela à travers les topics et mesurer l’impact de ces mentions.

Hawkeye vient juste de démarrer. Nous avons eu des retours incroyables jusqu’à présent mais ce n’est que le début. Nous travaillons dur pour le développer de plusieurs façons. En enrichissant le type de données que nous utilisons dans nos différents rapports. En créant de nouveaux rapports et visualisations de données. En travaillant à rendre notre IA capable de comprendre de plus en plus de choses sur le contenu. En fin de compte, nous voudrions que Hawkeye comprenne le contenu comme un être humain.
Parce que nous voulons être en mesure de valider la valeur fournie par Hawkeye et de l’itérer rapidement en fonction des commentaires, nous ne sommes pas encore prêts à rendre Hawkeye publiquement disponible. Pour au moins quelques mois, Hawkeye sera en version bêta privée – ce qui nous permettra d’exécuter des pilotes contrôlés avec des clients sélectionnés qui peuvent avoir un retour significatif de la content intelligence. Si cela vous intéresse, nous aimerions avoir votre avis ici et avoir une discussion.
Nous avons eu une aventure incroyable avec Scoop.it jusqu’à présent. D’une idée que nous avons découverte dans la Silicon Valley à la relocalisation à San Francisco d’une plate-forme avec 4 millions d’utilisateurs et des centaines de clients B2B, ça a été une aventure incroyable. Mais notre mission est loin d’être terminée. Les nouveaux défis et la technologie autour de la content intelligence nous montrent que la prochaine étape de notre voyage pourrait être encore plus excitante.

Be the first to comment on "La content intelligence : une nouvelle étape pour Scoop.it"